This article is based on Longformer: The Long-Document Transformer (Beltagy, Peters & Cohan, 2020, arXiv:2004.05150). The paper introduces a scalable attention mechanism for long documents; this article cuts the fluff and gets straight to the core concept, and the math, so you walk away with a complete, self-contained understanding of what Longformer actually does.
My advice: don’t read this article; just look at this image and you are good to go!
But if you want to learn some related concepts pertaining to sliding window attention then read the content below :)
The problem: self-attention is quadratic
Standard Transformer self-attention computes, for a sequence of length n, the following:
STANDARD SELF ATTENTION
Attention(Q, K, V) = softmax( Q·Kᵀ / √d_k ) · V
The bottleneck is Q·Kᵀ. Both Q and K have shape (n, d_k), so their product is an (n × n) matrix. Time and memory both scale as O(n²). For n = 512 this is manageable. For n = 4,096 or 16,384, it becomes either very slow or impossible on standard GPUs.
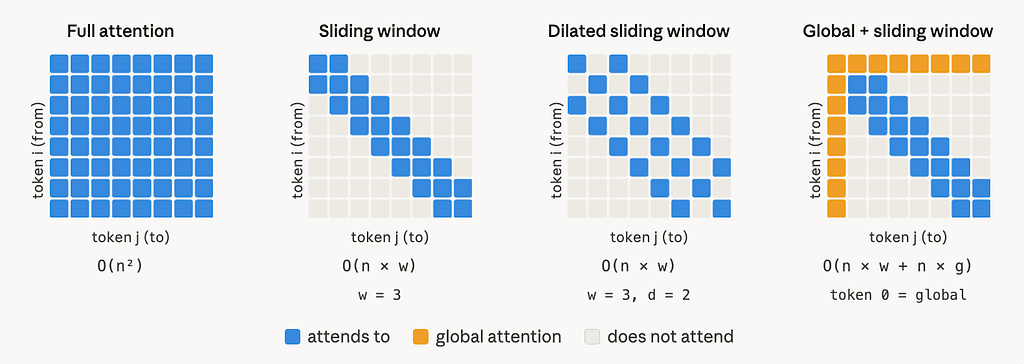
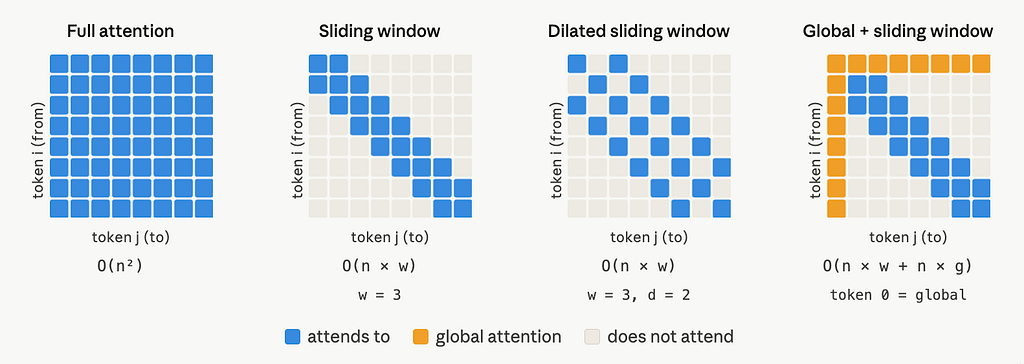
Longformer replaces this dense attention matrix with a sparse one, built from two components: a sliding window and a global attention layer.
Component 1: sliding window attention
Instead of letting every token attend to every other token, each token attends only to its neighbors within a fixed window of size w. Specifically, token i attends to tokens from index i — w/2 to i + w/2 (inclusive), that is w/2 tokens to the left and w/2 to the right.
SLIDING WINDOW COMPLEXITY
O(n × w)
Since w is a fixed constant (e.g. 512), this is linear in n. For a model with l layers, the receptive field at the top layer, meaning the span of input tokens each output token has indirectly seen, is:
RECEPTIVE FIELD AFTER L LAYERS
l × w
Each layer’s windowed attention feeds into the next, so representations from distant tokens gradually reach every position through stacking, exactly like how convolutional neural networks build global context through depth despite each kernel being local.
The paper also uses different window sizes per layer: smaller windows in the lower layers (which capture local syntax and token-level features) and larger windows in the higher layers (which build document-level representations). This balances compute with representation quality.
Component 2: dilated sliding window
To increase the receptive field without increasing compute, the window can be dilated by a gap factor d. Instead of attending to contiguous neighbors, token i attends to every d-th token within the window range, skipping the tokens in between.
DILATED RECEPTIVE FIELD
l × d × w
The number of tokens attended to per position remains w (fixed), so complexity stays O(n × w). But because those w attended positions are spread out by factor d, a single layer already sees context that is d times wider.
In practice, the paper uses dilation only on 2 out of 8 attention heads per layer. The remaining heads retain non-dilated (d = 1) windows. This lets some heads specialize in local context and others in longer-range context, which the ablation study confirms improves performance.
Component 3: global attention
[Bonus section; you can skip this]
Sliding window attention is good at building contextual representations locally. But some tasks need a token that has seen the entire sequence: classification needs a summary vector, and question answering needs the question tokens to be compared against every position in the document.
For these cases, Longformer paper adds global attention on a small set of pre-selected tokens. The rule is symmetric:
GLOBAL ATTENTION RULE
A globally-attended token g attends to every token in the sequence (positions 1..n). Every token in the sequence also attends back to g.
Let the number of globally-attended tokens be g. Since g is small and does not grow with n (it is determined by the task, e.g. 1 for a [CLS] token for a classification task), the added attention is O(n × g). Combined with the sliding window:
TOTAL COMPLEXITY
O(n × w) + O(n × g) = O(n) [since w and g are constants relative to n]
Two separate projection sets
Because sliding window attention and global attention play structurally different roles, Longformer uses two separate sets of linear projection matrices:
SLIDING WINDOW PROJECTIONS
Q_s, K_s, V_s → used for local windowed attention scores
GLOBAL ATTENTION PROJECTIONS
Q_g, K_g, V_g → used for global attention scores
All six are initialized to the same values as the original pretrained model’s Q, K, V weights. The separation gives each attention type its own degrees of freedom during finetuning, which the WikiHop ablation study shows is critical: removing the separate projections for global attention drops accuracy by 1.6 points, and removing global attention entirely drops it by 8.3 points.
The full picture in one place
STANDARD ATTENTION
Complexity: O(n²) | Every token attends to every token
LONGFORMER ATTENTION
For non-global token i:
- attends to tokens in [i — w/2, i + w/2] [sliding window]
- attends to all global tokens g₁, g₂, … [inbound global]
For global token g:
- attends to all n tokens in the sequence [outbound global]
Total complexity: O(n × w) + O(n × g) = O(n)