Apr 20, 2026/Tech
Linear Attention Explained: The Core Concept and the Math, Without the Fluff
This article cuts the fluff, gets straight to the core concept and math, and explains every variable as it appears. Nothing is left undefined.
building practical AI systems
session://blog/tech
$ find blog/tech -type f
### Tech Writings
Systems, ML, LLMs, and the engineering details that decide whether ideas survive reality.
13 tech articles
This article cuts the fluff, gets straight to the core concept and math, and explains every variable as it appears. Nothing is left undefined.
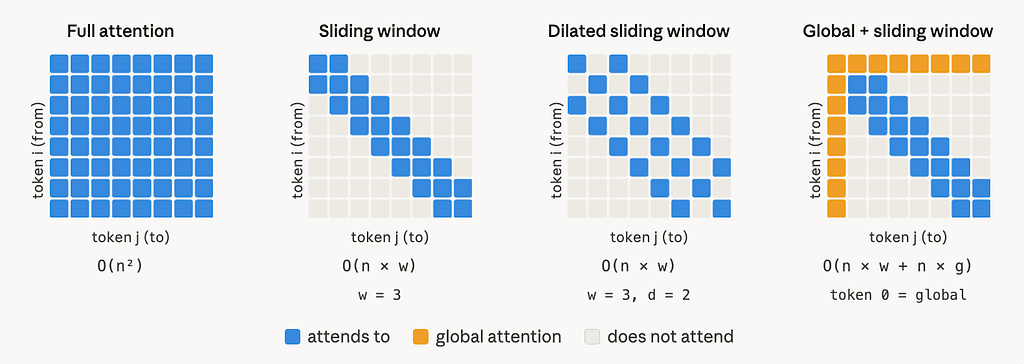
This article is based on Longformer: The Long-Document Transformer (Beltagy, Peters & Cohan, 2020, arXiv:2004.05150). The paper introduces a scalable attention mechanism for long documents;...
TL;DR: On public blockchains, your transaction sits in a visible waiting room before it goes through. Automated bots and block producers can read it, act on it, and leave you with a worse...

When an LLM generates a response, it stores intermediate computations called the KV cache in GPU memory at every step. Traditional serving frameworks pre-allocated memory for each request...

But there is a feature that quietly solves one of the most common sources of friction in everyday development. Many developers have heard about it. Very few actually use it in practice.

A beginner-friendly debugging story about static sites, Next.js, Google Analytics, and why production can behave very differently from local development.

But I’m starting to see the path forward more clearly. Let me share what I’m taking away from all this research and learning.

You can build the perfect model. Implement flawless pipelines. Have bulletproof monitoring. Deploy with zero downtime.

The unglamorous stuff. The debugging at 2am stuff. The “why is the model doing this?” stuff. The security vulnerabilities stuff. The “future me will hate present me for not documenting...

I had built a model. It worked beautifully on my laptop. 95% accuracy on my test set. Clean code. Fast inference.

I mean, I could explain transformers. I knew about attention mechanisms. I had read the “Attention Is All You Need” paper (okay, skimmed it).

Your loss function isn’t just a number that needs to go down. It’s a precise mathematical statement about what you care about and your model will give you exactly what you asked for, even...

So I’m starting a 7-part series this week to break down the fundamentals that actually matter.