Apr 20, 2026/Tech
Linear Attention Explained: The Core Concept and the Math, Without the Fluff
This article cuts the fluff, gets straight to the core concept and math, and explains every variable as it appears. Nothing is left undefined.
building practical AI systems
session://blog
$ cat featured/tech.log
Systems, ML, LLMs, and the engineering details that decide whether ideas survive reality.
13 tech articles
This article cuts the fluff, gets straight to the core concept and math, and explains every variable as it appears. Nothing is left undefined.
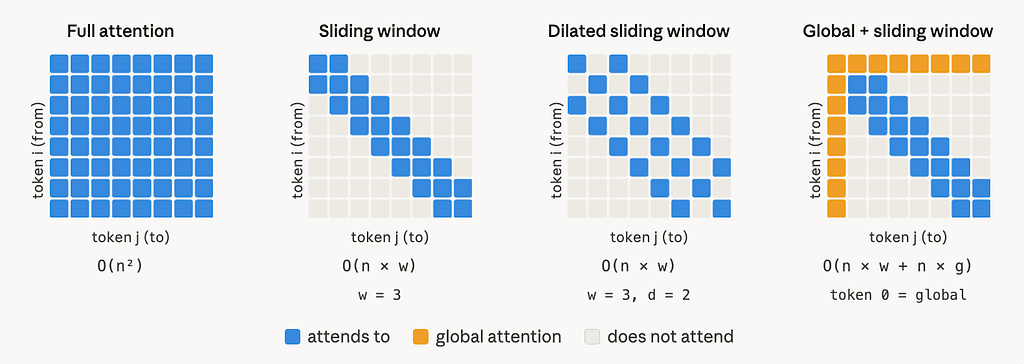
This article is based on Longformer: The Long-Document Transformer (Beltagy, Peters & Cohan, 2020, arXiv:2004.05150). The paper introduces a scalable attention mechanism for long documents;...
TL;DR: On public blockchains, your transaction sits in a visible waiting room before it goes through. Automated bots and block producers can read it, act on it, and leave you with a worse...

When an LLM generates a response, it stores intermediate computations called the KV cache in GPU memory at every step. Traditional serving frameworks pre-allocated memory for each request...

But there is a feature that quietly solves one of the most common sources of friction in everyday development. Many developers have heard about it. Very few actually use it in practice.

A beginner-friendly debugging story about static sites, Next.js, Google Analytics, and why production can behave very differently from local development.
$ cat featured/beyond-tech.log
Notes on growth, mindset, inner architecture, and the human side of becoming better.
5 non-tech articles
Much of the overwhelm around AI comes from familiar software ideas being dressed up in new vocabulary. Reframing it that way makes keeping up much easier.

Building is getting easier. The only thing that matters now is a GOOD IDEA and FREAKING GREAT EXECUTION.

Agents will be far more useful to people who have structured, persistent memory. (I have started using obsidian)